- 發佈於
推薦文章: 效率過高會使一切變得更糟
接續推論到 (沒那麼悲觀的) AGI 風險
- 作者

- 作者
- ChrisTorng
PS: 本文不是摘要,強烈建議自行進入原文,(以翻譯) 自行閱讀完整文章。
Too much efficiency makes everything worse: overfitting and the strong version of Goodhart’s law
與直覺相反,效率的提高有時會導致更糟糕的結果。幾乎所有地方都是如此。我們將這種現象命名為古德哈特定律的強版本。舉個例子,透過標準化測驗更有效地集中追蹤學生的進步似乎是一個好主意,以至於善意的法律強制要求這樣做。然而,測驗也激勵學校更專注於教導學生如何做好測試,而不是教導廣泛有用的技能。結果,它可能導致整體教育成果變得更糟。類似的例子在政治、經濟、健康、科學和許多其他領域比比皆是。
當一項度量成為目標時,它就不再是一個好的度量。
由機器學習的過擬合推論到古德哈特定律:
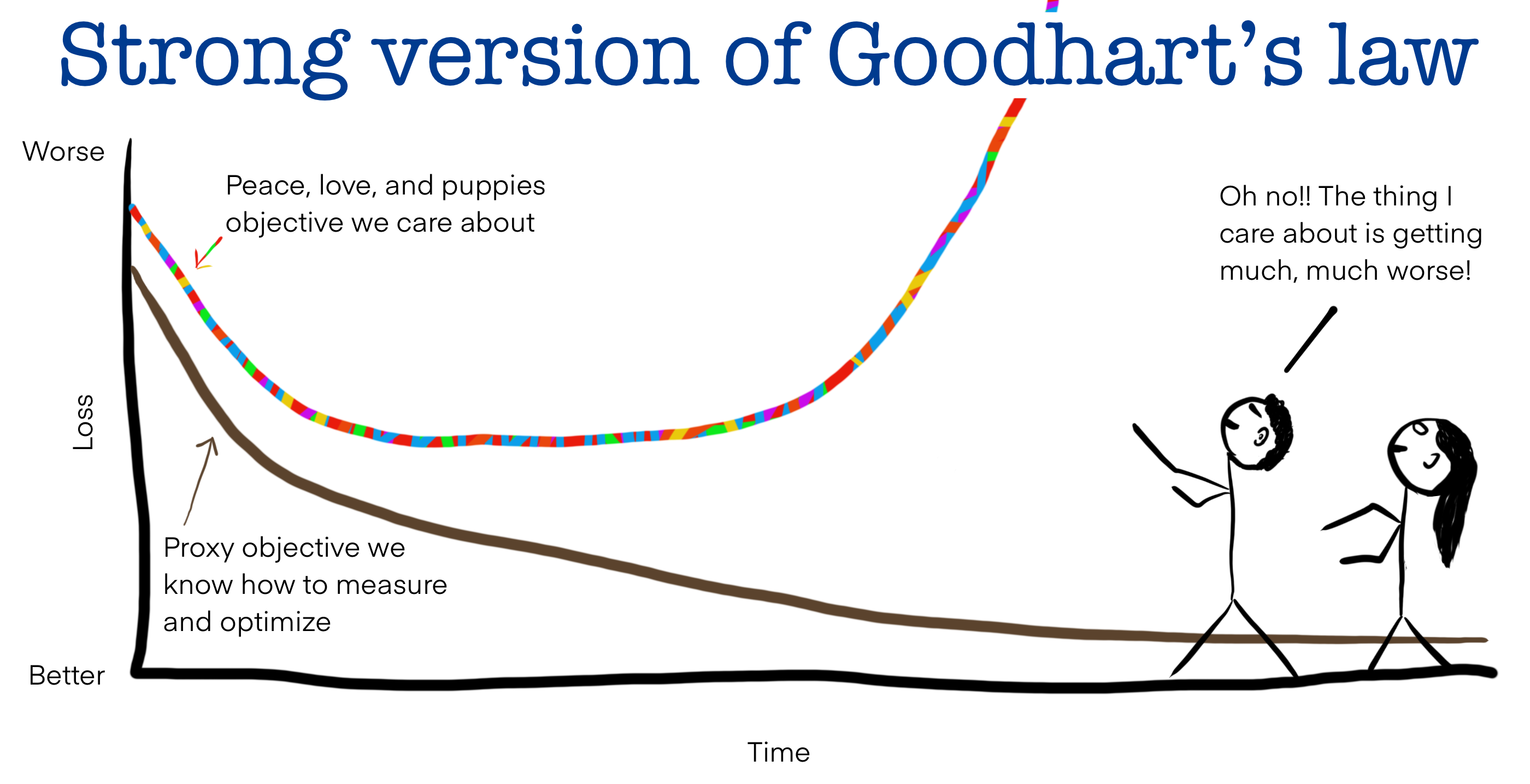
我們關心的結果會在一段時間內有所改善……然後它們會急劇惡化。
因此追求度量目標不僅是原定律所講的不好而已,(強版本說) 還會越來越糟糕。僅舉其中一例:
目標:美好生活
代理:最大化大腦中的獎勵途徑
強化版的古德哈特定律會導致:物質成癮、賭博成癮、在推特上浪費時間
我們如何減輕過擬合和古德哈特定律的強版本所帶來的問題?
- 更好地將代理目標與預期結果結合
- 在系統中加入正規化懲罰
- 向系統注入雜訊
- 及早停止
- 限制能力/容量
- 增加能力/容量
如果人工智慧能夠實現一件事,那就是在很短的時間內提高幾乎所有任務的效率。我們將需要同時處理大量不同的不良副作用,就像我們協作解決方案的能力也受到干擾一樣。
後續文章繼續探討 AGI 風險:
The hot mess theory of AI misalignment: More intelligent agents behave less coherently
許多流行的對超級智慧人工智慧的恐懼都基於一個未明確的假設,即隨著人工智慧變得更加智能,它也會變得更加_連貫_,因為它會偏執地追求一個明確的目標。我討論了這個假設,並進行了一個簡單的實驗來探討智力和連貫性之間的關係。這個簡單的實驗提供的證據表明事實恰恰相反——隨著實體變得更加聰明,它們的行為往往變得更加不連貫,並且不太能被描述為追求單一明確的目標。這表明我們不應該擔心 AGI 由於價值調整錯誤而帶來生存風險。
作者由一個簡單的實驗,推論認為 AGI 的能力越提升,行為會開始變得更混亂,無法追求單一明確的目標,因此風險並不高。
Brain dump on the diversity of AI risk
人工智慧有能力以奇妙和可怕的方式改變世界。我們應該努力讓美好的結果比可怕的結果更有可能發生。為此,以下是我對人工智慧可能如何出錯的想法的粗略概述。我不是第一個有這些想法的人,但收集和建構這些風險對我很有用。希望閱讀它們對您有用。
我最擔心的包括對人類的有針對性的操縱、自主武器、大規模失業、人工智慧監控和征服、社會機制普遍失效、權力極度集中以及人類控制的喪失。
我想強調的是,我預期人工智慧帶來的好處遠大於壞處,但實現這一目標的一部分是仔細考慮風險。
詳列了許多未來 AI 的可能風險項目。